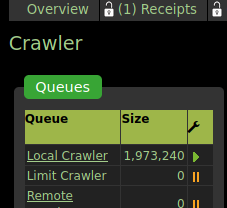
The “size” value for it keeps going up, even when I don’t have any crawls running. What is the size? Bytes? Pages?
What’s it doing? Is it a backlog of some sort from pages I’ve crawled?
The “size” value for it keeps going up, even when I don’t have any crawls running. What is the size? Bytes? Pages?
What’s it doing? Is it a backlog of some sort from pages I’ve crawled?
Yes, there.
That’s the Queue for Local Crawler. You can see it’s content in Crawler > Queues > Local. There you’ll see the domains and pages enqueued for crawling and probably you can distinguish their origin.
Reasons can be many, misconfigured Advanced crawler, or some sort of automatic crawl (Heuristics, Import…), examine Queue and you’ll know more.
Trying to open the queue was timing out, I imagine because there was too many pages queued (45 million), but looking at the index browser, I did find one domain with that many pending crawls. And that website doesn’t have 45 million pages, so I’m guessing I botched it up with dynamic pages.
This was a website that whose crawl I already terminated in the crawling monitor. I don’t understand how the number of pages queued kept going up.
Also, these pages weren’t getting counted in the Crawler PPM on the Crawler Monitor page, nor were they being listed on that page when they were crawled. So I guess I don’t understand how this works?
Yes, I observed that the queue operations are sort of ineffective, when working with millions of links. If you wanna fresh start over, you can try to delete the queue manually (with yacy down), by deleting DATA/INDEX/freeworld/QUEUES/CrawlerCoreStacks content and start it up again.
While starting your crawl again, make sure you understand the mechanism how the links are added to queue, especially the filters in Advanced Crawler, as discussed in the documentation and recently in the forum as well.
But still, how to limit the maximum size of a local queue without stopping work?
So that during operation the crawler itself does not consume excessive resources, so as not to periodically delete the queue manually.