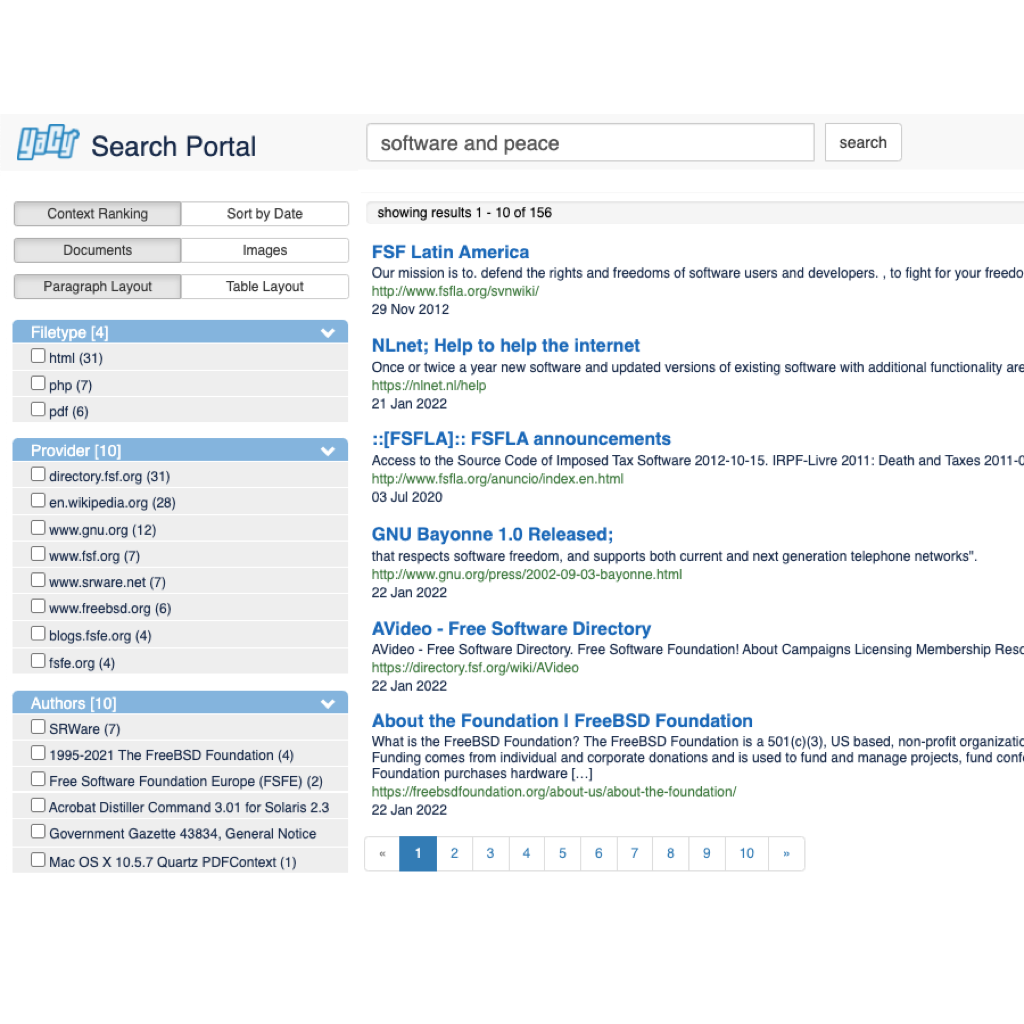
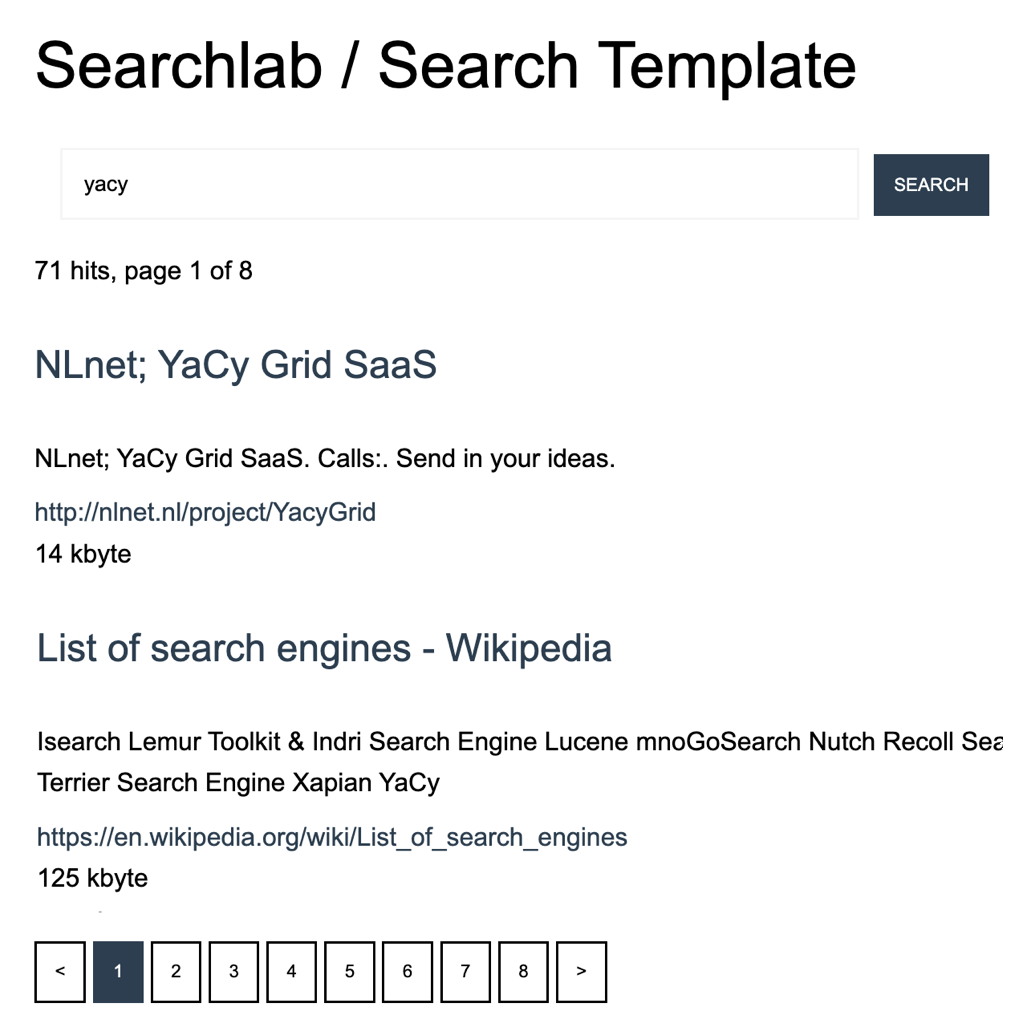
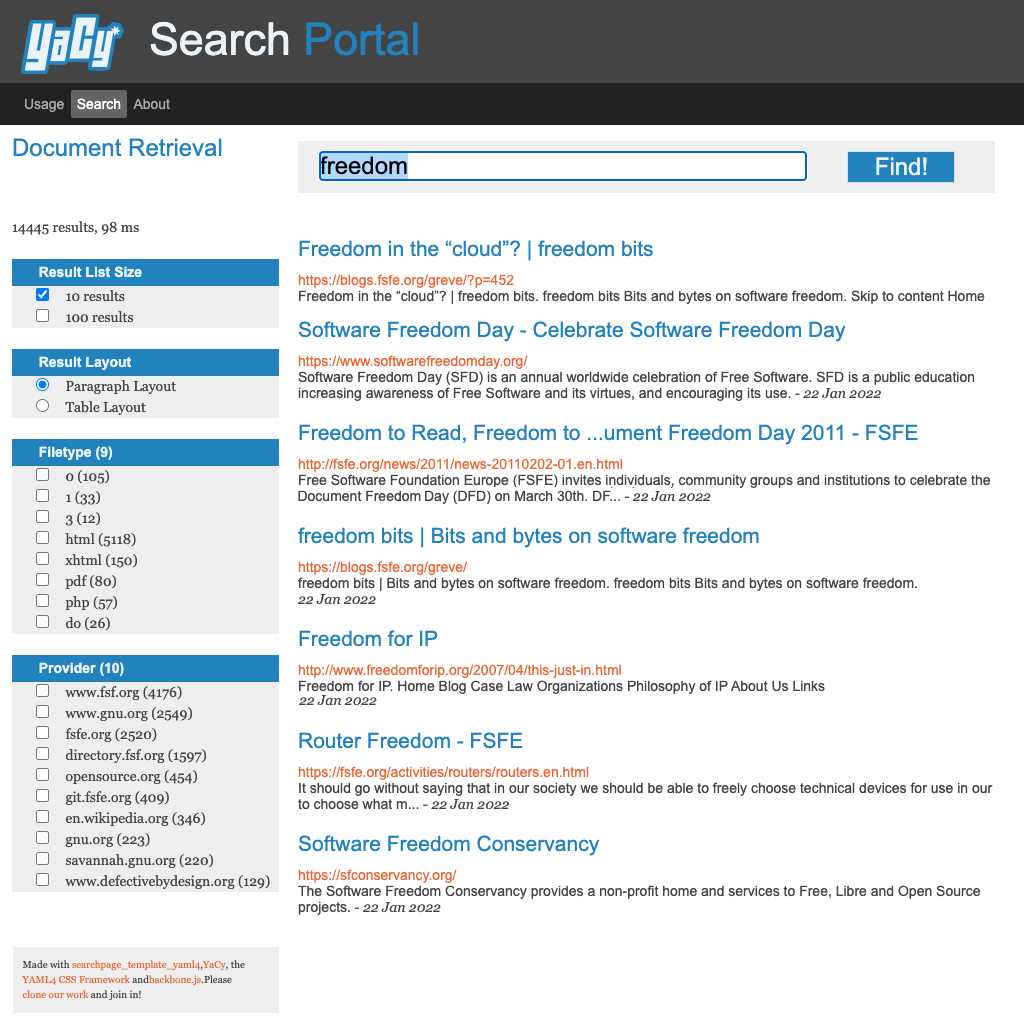
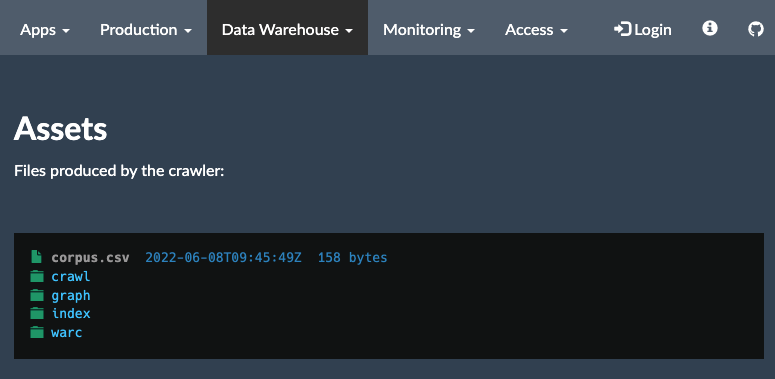
For quite some time I am working on a concept for a portal using YaCy Grid as Crawler/Indexing engine. It is about two years ago that I tried to find a sponsor for the portal. Today not only the project has started, it also has reached it’s first milestone!
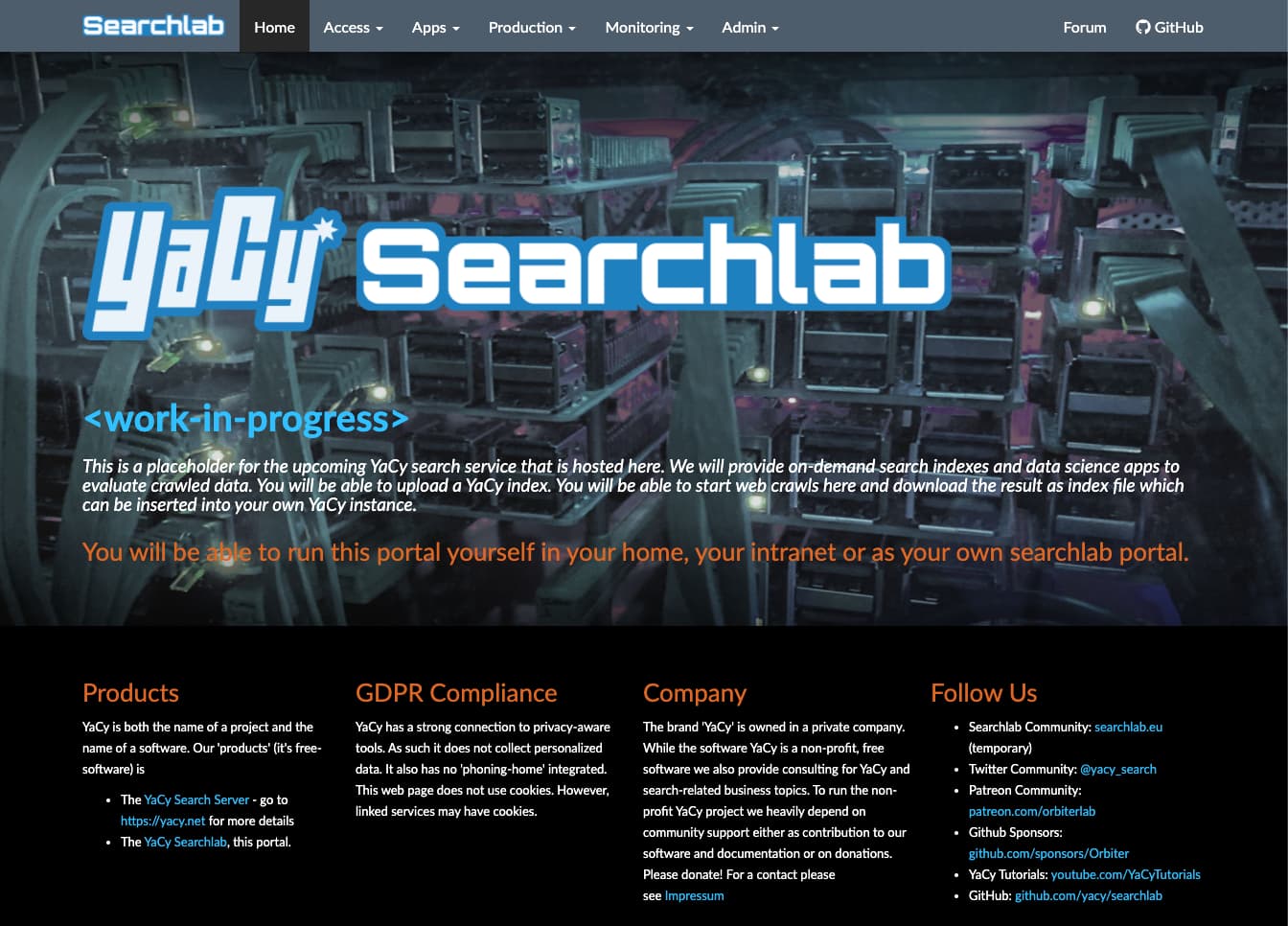
The searchlab portal is actually live right now - but I do not share the temporary link until the new searchlab portal can be - maybe you guess it - here, at the same place where the forums are. This means we must migrate this forum to a subdomain of searchlab.eu - I will keep you updated.
The YaCy Searchlab project is kindly sponsored by NLnet and YaCy Patreon patrons. I would kindly ask you here to become a patron as well to support my work on YaCy and the searchlab.
The six milestones of the project explain pretty well where the project is going and what you can expect:
- M1 - Setup documentation and portal page (
 done!)
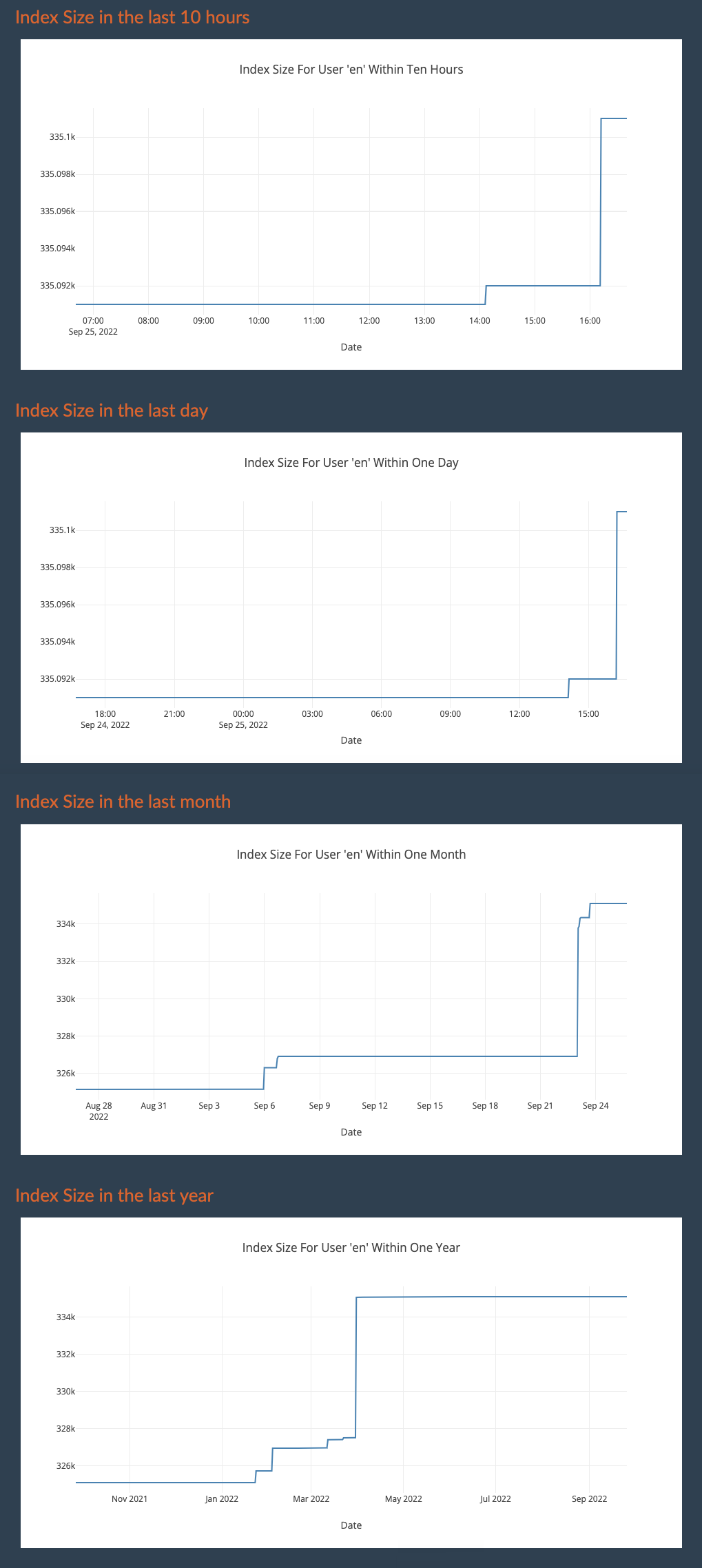
done!) - M2 - Integration of YaCy Grid into SaaS Portal including Search Portal ( done!)
- M3 - Data Studio: Application Widget Framework
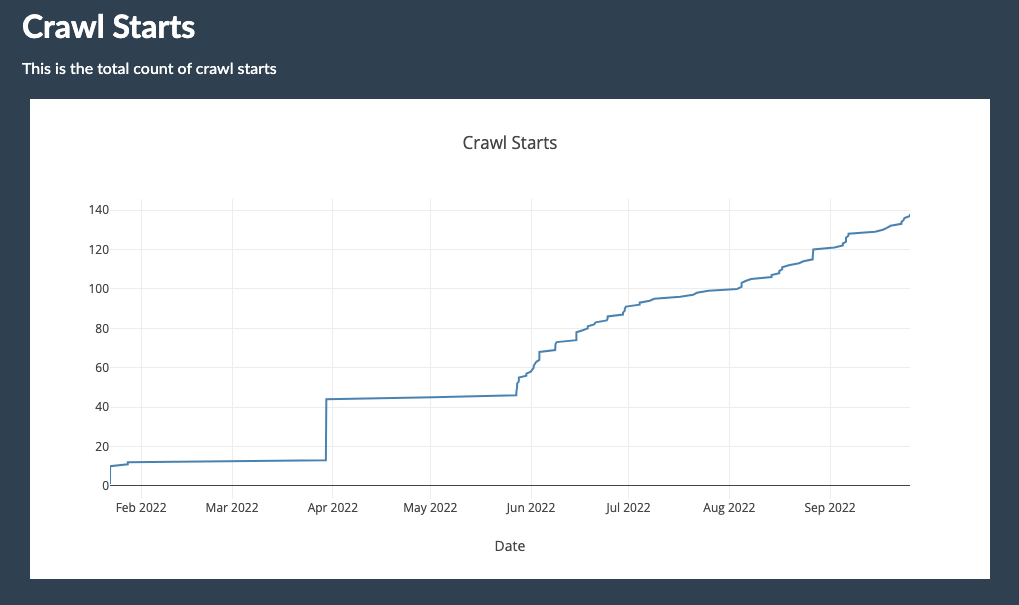
- M4 - Front-End and Back-End for Crawl Start management and Data Warehouse
- M5 - Integrating an ACL Framework for Account Management
- M6 - Sponsor functions
A lot more details is contained in the README of the searchlab repository at github.
If you actually want to see the portal yourself, you can easily do so by using docker:
docker run -d --rm -p 8400:8400 --name searchlab yacy/searchlab
.. end then open http://localhost:8400 in your browser.
If you have any ideas suggestions or questions, please let me know!