Hi all,
I’ve been experimenting with a non-invasive way to reduce crawler stalls caused by hosts that repeatedly enforce crawl-delays, without touching YaCy core logic (HostQueue, CrawlQueues, etc.).
Instead of patching Java, this approach observes YaCy’s own log output and feeds the result back into the existing blacklist mechanism.
Motivation
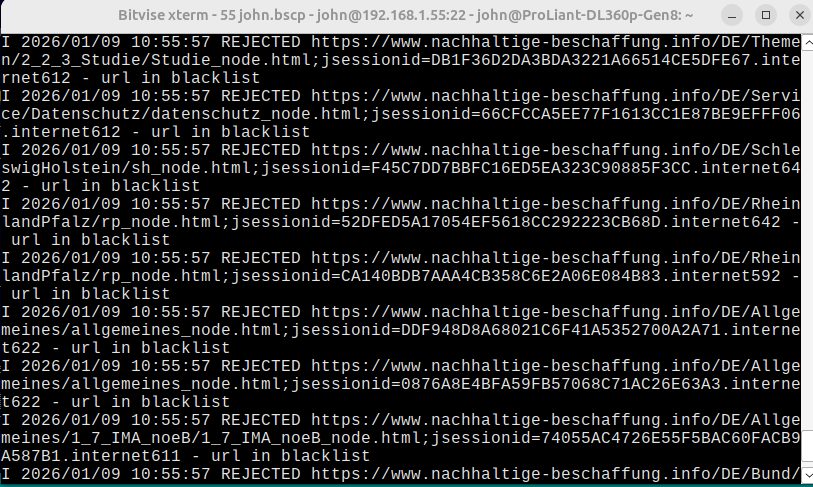
When YaCy encounters repeated messages like:
HostQueue * forcing crawl-delay of 85 milliseconds for www.example.com
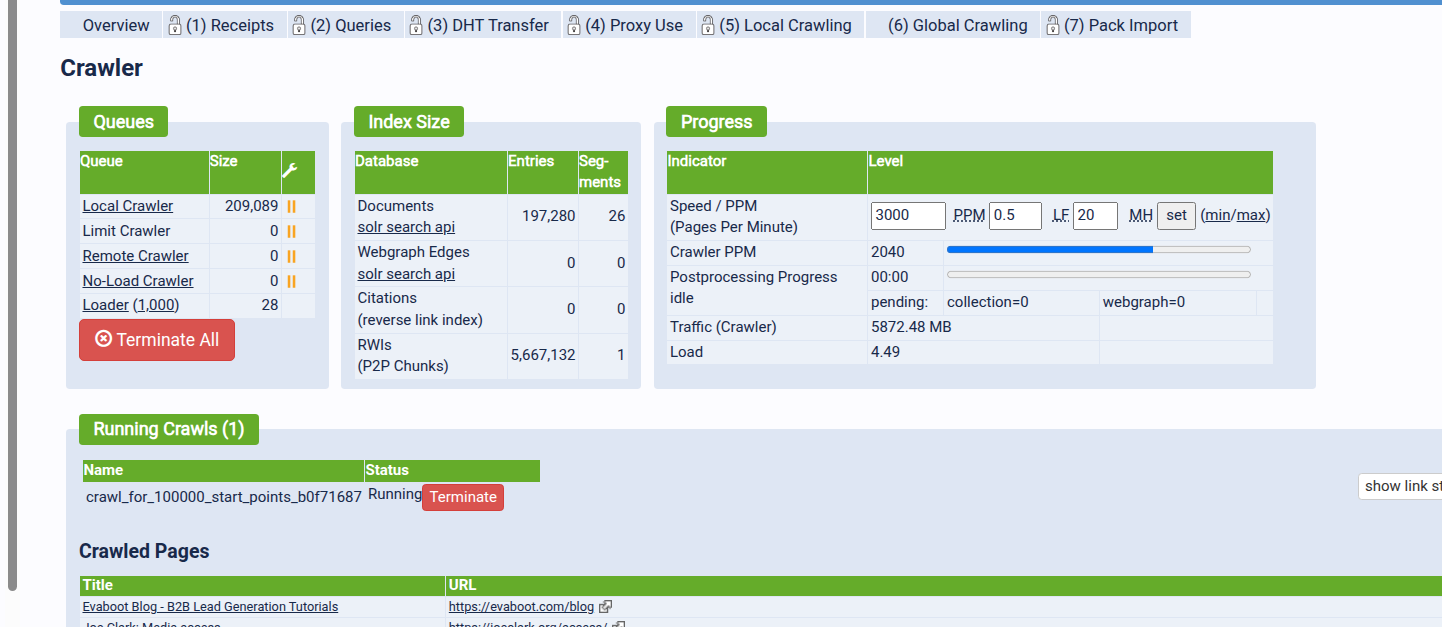
The crawler can end up spending disproportionate time idling on a small set of slow or defensive hosts.
This is not aggressive crawling — it’s the opposite: backing off early and letting other hosts proceed.
Design goals
-
 No Java changes
No Java changes -
Fully reversible
-
Respects robots.txt
-
Uses YaCy’s existing blacklist engine
-
Can be turned off instantly
-
Reputation-safe
How it works
-
A small shell script scans
yacy00.log -
Extracts hosts where YaCy already enforced a crawl-delay
-
If the delay exceeds a threshold (e.g. 50 ms)
-
Adds the host to a dedicated blacklist file
Example blacklist file:
DATA/LISTS/autoblack.default.black
This keeps manual blacklists and auto-generated rules clearly separated.
Example script (simplified)
#!/bin/bash
YACY_LOG="DATA/LOG/yacy00.log"
BLACKLIST="DATA/LISTS/autoblack.crawldelay.black"
CRAWL_DELAY_THRESHOLD=50
touch "$BLACKLIST"
grep "forcing crawl-delay" "$YACY_LOG" | while read -r line; do
delay=$(sed -n 's/.*forcing crawl-delay of \([0-9]\+\).*/\1/p' <<< "$line")
host=$(sed -n 's/.* for \([^: ]\+\).*/\1/p' <<< "$line")
[[ -z "$delay" || ! "$delay" =~ ^[0-9]+$ ]] && continue
[[ -z "$host" ]] && continue
[[ "$host" =~ ^[0-9]+\.[0-9]+\.[0-9]+\.[0-9]+$ ]] && continue
if (( delay >= CRAWL_DELAY_THRESHOLD )); then
rule="$host/*"
if ! grep -Fxq "$rule" "$BLACKLIST"; then
echo "# auto-blacklisted: crawl-delay ${delay}ms" >> "$BLACKLIST"
echo "$rule" >> "$BLACKLIST"
fi
fi
done
Restart Yacy
Scheduling (recommended)
Run every 5 minutes via cron:
*/5 * * * * flock -n /tmp/autoblack.lock /path/to/autoblack.sh
This prevents overlapping runs.
Why not integrate into HostQueue?
That may be worth discussing later, but keeping this external has advantages:
-
avoids fork maintenance
-
avoids accidental global behavior changes
-
easier to test, tune, or discard
-
keeps YaCy’s reputation logic conservative
This behaves more like adaptive politeness, not aggression.
Feedback welcome
I’m interested in:
-
whether others see similar crawl-delay bottlenecks
-
thoughts on threshold speed
-
ideas for optional expiry (e.g. auto-remove after N days)
-
whether this should stay external or become a configurable feature later on